IRiS is developed by Ignition - Visit the Ignition website here.


IRiS | 9 June 2026

Introducing the IRiS Assistant.
The argument is settled: meaning has to be built into your data before AI can use it. Two years ago that was genuinely contested. Today the industry has converged on it, and on the diagnosis that follows. Enterprise AI foundations break in the transformation layer. Not ingestion. Not the consumption layer. The middle.
Analysts point to the transformation layer as the weakest link. Practitioners tracing one prominent vendor's architectural advantage land on the same belief: meaning must be encoded upfront, not figured out later. This series has made that case across six articles.
Nobody is seriously disputing the what or the why anymore. The honest objection has always been the how.
Deciding what “customer” means across four source systems. Identifying Business Keys. Resolving conflicts. Capturing definitions from domain experts who have three other priorities. That work is where model-first gets expensive. It is the upfront cost a code-first approach defers, and the reason teams sometimes choose the faster path anyway. Not because they think it is better, but because they need to ship.
Quickly delivering a model-first solution is the problem the IRiS Assistant was built to solve.
Before a single line of code gets written, someone has to do the design work. An architect sits with source and domain experts, reads the metadata, profiles the data, and works through a sequence of decisions that sound simple but take real judgement to answer well.
What is the natural key for this entity, and is it stable across a source system migration? Does this update pattern represent a multi-active table, or a single record that gets replaced? Does this relationship need full historisation, or is non-historised the right call?
Then comes definition capture. What does “active” mean here? Which source wins when two systems disagree? That last one is not a technical conversation. It is a governance conversation that needs a business owner to decide, and those take time to schedule, navigate, and document.
On a reasonably complex source system, this takes days. Multiply by the number of source tables, then by the number of source systems. That is where the data team staffing numbers come from. It is not the code generation that needs a department of specialists. It is the design work that precedes it.
Done well, everything downstream is faster and easier to extend. Done under pressure, the debt accumulates quietly and surfaces later, when it is expensive to fix. The upfront modelling effort is the real trade-off of model-first, and the question is whether you pay now or later. Model-first teams pay now and build a compounding asset. Code-first teams defer, and accumulate debt.
The IRiS Assistant guides an engineer, analyst, or architect through the complete design process for a source system, from source table to production-ready metadata, in a single conversation.
It connects directly to source tables in the landing layer, reads the metadata, and profiles a data sample automatically. It does not start with assumptions about what the data means. It starts with what the data contains.
From there it conducts structured Q&A grounded in what the profiling found, not in generic templates. It covers source system ownership and context, the business meaning of key fields, Business Key identification confirmed through conversation rather than guessed from column names, multi-active Satellite patterns, non-historised Link candidates, and PII classification flagged automatically for confirmation.
 Throughout, it cross-references the existing model. If Customer is already modelled with an established Hub Business Key and naming convention, the new table's relationship to it is checked for consistency before any decision is confirmed. The model stays coherent as it grows.
Throughout, it cross-references the existing model. If Customer is already modelled with an established Hub Business Key and naming convention, the new table's relationship to it is checked for consistency before any decision is confirmed. The model stays coherent as it grows.
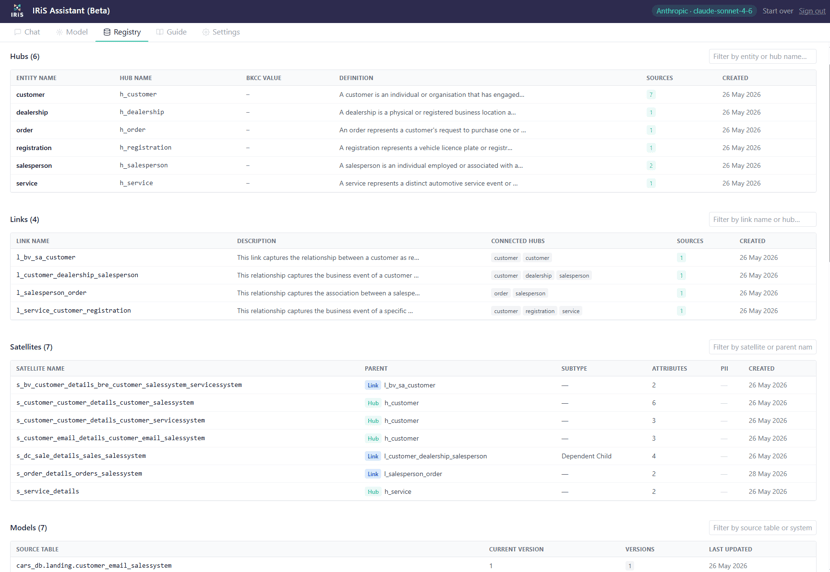
Once the design is confirmed, the Assistant generates the IRiS metadata and lands it directly in the code repository, giving the team a versioned, auditable record of every design decision from day one. The completed design is rendered in the model visualisation layer, so stakeholders can see the emerging structure before any code is generated.
The output is not a diagram or a set of recommendations. It is the implementation artefact itself. The design conversation and the metadata are the same thing.
The definitions captured during the design conversation have a life beyond the immediate modelling task. The Assistant builds and maintains a project glossary as it goes, applying existing definitions where they exist and drafting new ones for review where they do not. The glossary stays current, rather than becoming a documentation task that gets deferred until the people who made the decisions have moved on.
This matters because those same definitions are what the AI stack needs to reason correctly later. The glossary underpins the Gold layer views, the definitions an AI system uses to answer questions about current or historical data, and the metadata that lets an AI agent choose the right source when two conflict. All of it traces back to decisions made at design time.
It also produces something more valuable as a by-product: an ontology. When the Assistant identifies a Hub for Customer, confirms its Business Key, establishes its relationship to Order through a Link, and captures how a Customer is distinguished from a Prospect, that is an ontological description of the Customer concept and its relationships. When it captures that “active” is defined by a non-zero billing balance rather than a CRM login flag, that is a formal constraint encoded in the model.
 Building an enterprise ontology intentionally is expensive. One prominent but controversial vendor built its competitive advantage on exactly this, and the pipeline complexity required to replicate it is one of the genuine criticisms of that approach. The Assistant produces a structurally equivalent result as a natural consequence of doing the implementation correctly, source table by source table, as the Lakehouse grows. You are not building an ontology and then building a data model. You are building them together.
Building an enterprise ontology intentionally is expensive. One prominent but controversial vendor built its competitive advantage on exactly this, and the pipeline complexity required to replicate it is one of the genuine criticisms of that approach. The Assistant produces a structurally equivalent result as a natural consequence of doing the implementation correctly, source table by source table, as the Lakehouse grows. You are not building an ontology and then building a data model. You are building them together.
That is what “meaning precedes intelligence, the model is the message” means in practice.
It is worth being direct about what the Assistant is, and is not, at least in its current version.
It handles the structural pattern recognition, the cross-referencing against the existing model, the consistency enforcement, and the metadata generation. These are the repeatable, rule-based, time-consuming parts: the mechanical labour that currently consumes most of the hours between understanding a source system and having a conforming design.
The parts that need judgement stay with the people who have it. Is this relationship genuinely non-historised, or does the source system just not capture history for it yet? That is an architectural call that takes experience. Modelling decisions also surface candidates for Business Vault rules, such as status code interpretations or cross-source resolution logic. The Assistant flags these during the conversation, so they are captured as requirements rather than discovered later as debt.
This is not automation in the sense of removing architectural judgement. It is acceleration in the sense of removing the mechanical work that surrounds it.
The multi-year programme objection has ended more Data Vault conversations than any architectural argument. Not because the methodology is wrong, but because the honest cost of doing it well made the upfront investment look prohibitive against a code-first approach that ships faster.
IRiS already addressed half the equation. Code generation from a compliant design runs at 4.5 times the pace of manual implementation, with 65% less engineering effort. For teams that could get through the design phase, the build phase was already tractable.
The Assistant addresses the other half. The design phase, the part that took the most senior architects and the most elapsed time before any code was written, now has a structured, repeatable, AI-guided process. The work that took days takes a fraction of that. The output is not a diagram to be translated. It is the implementation artefact, landed in the repository, consistent with the existing model, with definitions captured and the glossary updated. With the IRIS Assistant data teams can now deliver standardised models and consistent code at more than ten times the speed.
This series has made a single argument: enterprise AI does not fail because of the models. It fails because of the transformation layer, the part that turns distributed, multi-source records into an integrated, governed, historically complete view of the enterprise.
DV2 solves that structurally: stable entity identity, complete temporal history, explicit relationships, versioned definitions, end-to-end lineage. The emergence of AI has made well-described, ontologically structured data mandatory rather than aspirational, and the same technology that raised the bar has provided the means to meet it. With IRiS and AI, we are reducing the dependency on deep expertise in graph-oriented and ontological modelling. The DV2 model remains the right foundation, and its value is now more tangible: we are generating descriptive, AI-ready metadata that describes your business in a form a machine can reason over.
The honest objection was never architectural. It was practical. Doing it correctly takes time, takes experienced architects, and involves an upfront investment that is hard to justify against the pace stakeholders want. IRiS addresses the build phase. The Assistant addresses the design phase. Together they make model-first Data Vault deliverable at the pace modern programmes demand.
Meaning precedes intelligence. The model is the message. And for the first time, you can build the right model at the pace the business requires.
This article is part of the Data Intelligence Series by Ignition Data. IRiS is available on the Microsoft Azure Marketplace, supporting Microsoft Fabric, Snowflake, and Databricks.







